Introduction
After a 3-year break from learning Spanish, I decided to find a fun and efficient way to reconnect with the language -- creating an AI document translation app that generates bilingual documents, readable from my Obsidian-inspired Markdown Viewer web app. Both applications run on my VPS, the Markdown Viewer being publicly exposed via Caddy.
The Translation Structure
The following is the output document’s translation structure:
- Spanish text
- original English text
- Spanish text
- original English text and so on until the end of the text
The structure ensures that I am able to maintain a frame of reference to the original tone and language while I am reading the Spanish text. This structure allows the formation of reference points between the flow of the Spanish text versus the English written language, and helps grasp tone and meaning effectively. I’m certain there are better ways to learn the language but this has been quite interesting thus far. While I’m sure this is not the most efficient way to learn the language, I’ve found this approach to be quite engaging. The fact that I’m learning through something I built also gives me motivation.
The Translation Workflow
The app has Docker images for web API and CLI versions, though I primarily use the CLI version. There are only three inputs:
urlof the webpage to be translated (mandatory),namedefines the name to save the document by, defaulting to the OpenGraph page title if none is provided, andcachedefines whether the crawler should use use cached webpage data for the given URL, defaulting toTrue.
The web crawler extracts the webpage content, which the LLM then translates using the above structure, and the resultant document is saved to the output directory. Crawled data and its translation are also persisted in a Postgres database.
You can check the core application logic here.
Web Crawler Configuration
Crawl4AI is my web crawler of choice, it crawls the given URL, prunes the content and returns a clean Markdown result. Although its dependencies increase the Docker image size, the trade-off is acceptable since the crawler runs locally, and instantiates a headless browser session. It also caches previously crawled pages, fetching content instantly for repeated URLs.
Sample Crawl4AI output
| |
|
| |
Translating the Crawled Data
The choice of OpenRouter as the LLM provider unlocks access to hundreds of LLM models with a single API key. This allowed for rapid experimentation to find the right model for my needs. I currently use Google’s Gemini 2.0 Flash-Lite for its affordability and speed, while handling effective translation and extraction of relevant content from the crawled text body.
It can however, occasionally fail to structure the translated content under headings properly, moving the text body under the English heading instead. This hasn’t bothered me in practice, and I believe this can be corrected with further tweaking of the LLM prompts.
Brief on AI Usage and Observability
PydanticAI was quick to setup and use with OpenRouter for my straightforward use case, and it is apparently easy to configure for more complex tasks in the future. Integrating Logfire with PydanticAI for agent observability was as easy as passing a boolean parameter to the Agent object instance. Logfire itself requires just a few lines of code and an API key acquired from its web dashboard.
Observability data will help keep track of draw comparisons between usage costs of various models, when translating particular documents.
Token usage and cost for a long, text-only article, observed in Pydantic Logfire 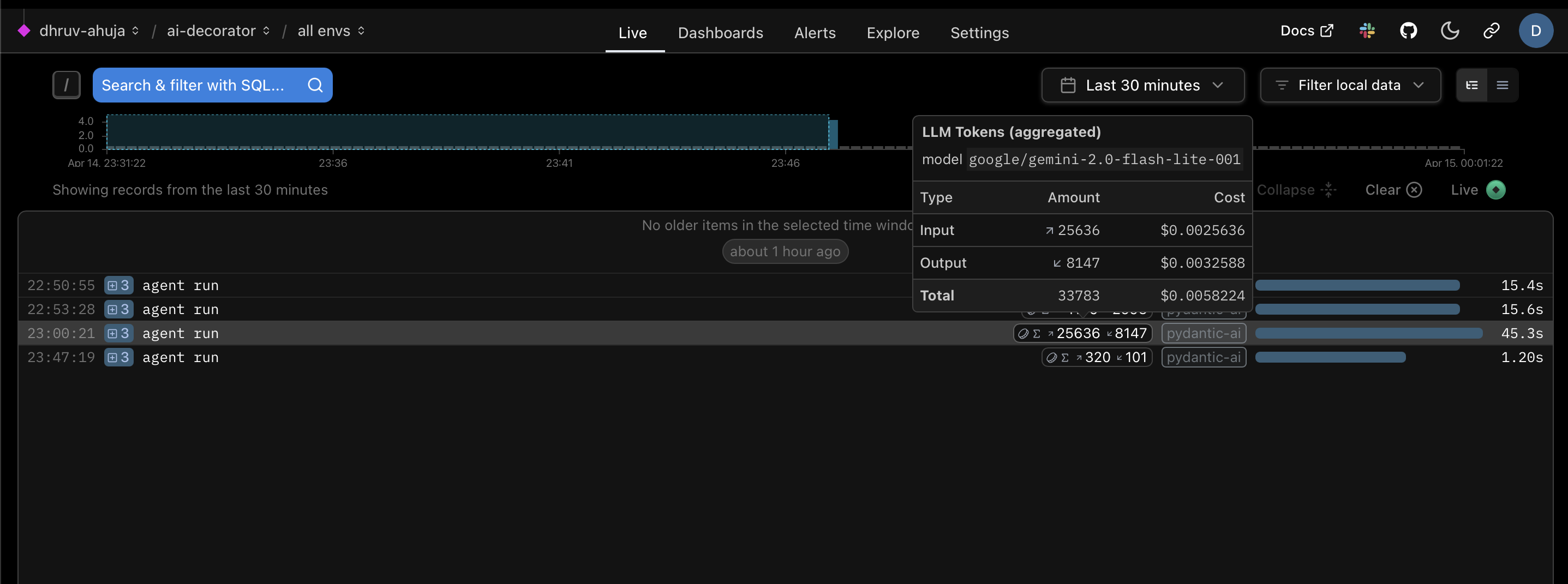
Consuming the Output
I trigger the application using Docker as a removable container, using something like
The app-network Docker network connects the app to a shared Postgres instance, which stores crawled content, translated outputs, and metadata for future reference. A simple Markdown Viewer Node webapp scans the output directory and lists all translated documents along with #public tagged notes, making them accessible via a clean web UI.
Sample document output in the Markdown Viewer app, where example.md is the translated document 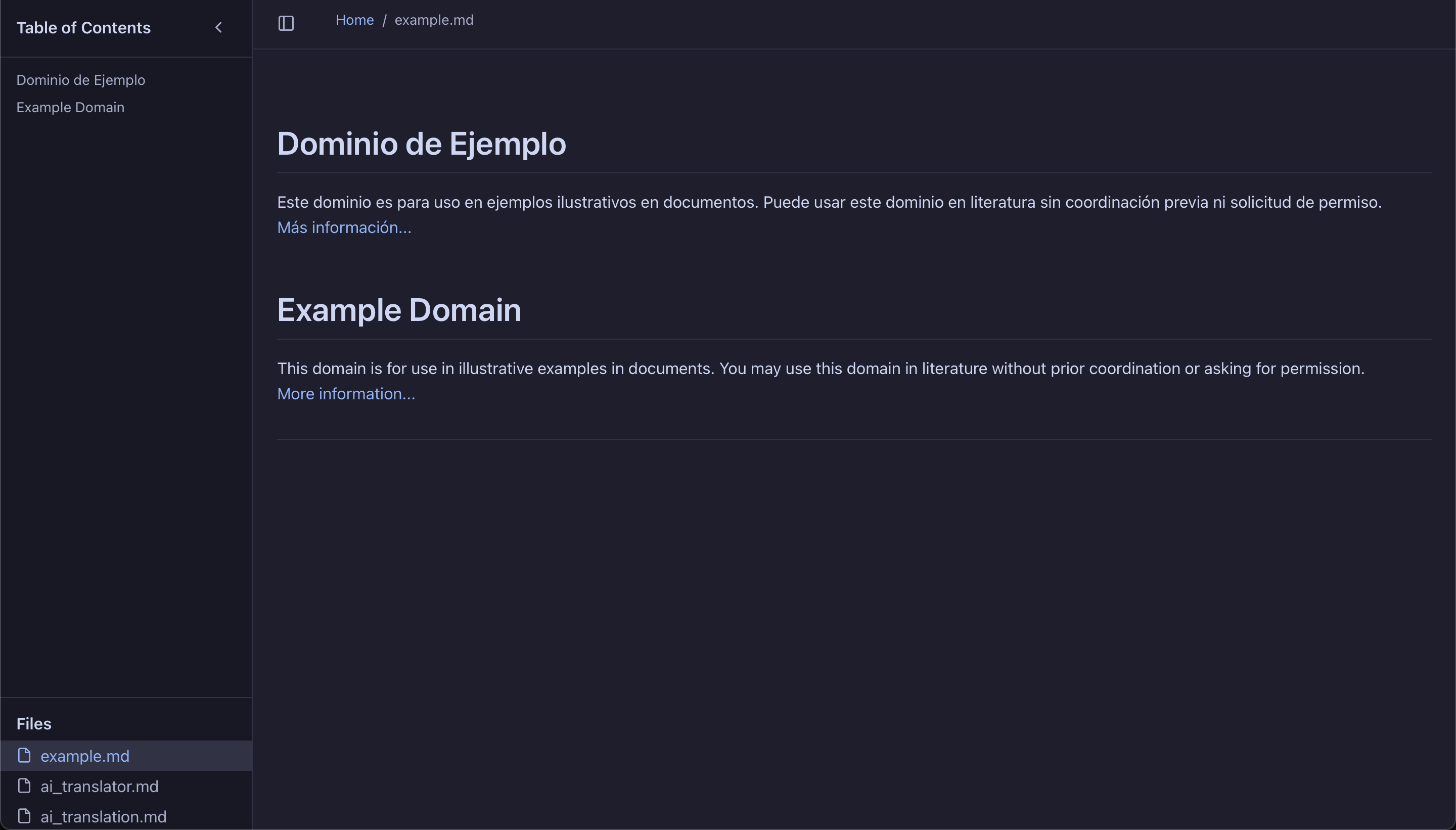
Conclusion: AI For the Win
I have enjoyed working on the application and the surrounding tooling that I’ve built to accomplish my goals. Having AI services such as v0.dev is a godsend for creating designs and POCs, like the Markdown Viewer that emulates Obsidian’s look-and-feel. AI is enabling us to build at a breath-taking pace, with increased emphasis on the desired outcome rather than the boilerplate and particulars of a language.
In this case, I did not have to learn Node syntax to prepare a functional script, while acutely reviewing and understanding the rationale behind the code. I similarly wrote a toy Go app to backup my VPS’ crucial data to S3 with certain conditions, in a couple hours.
Finally, I’ll be relearning Spanish through content I enjoy. I am deferring improvements to the code or the features, as it’s time to actually use I’ve built!